

CHCI@VT Prominently Featured at IEEE VL/HCC 2025
October 6, 2025

Numerous CHCI@VT faculty and students have contributed to the 42nd IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC 2025), October 7-10, in Raleigh, NC, including several chair and committee roles, 7 research papers, 3 workshop contributions, and 1 graduate consortium talk. IEEE VL/HCC is the premier international forum for research on visual languages and human-centered computing. Established in 1984, the mission of the conference is to support the design, theory, application, and evaluation of computing technologies and languages for programming, modeling, and communicating, which are easier to learn, use, and understand by people.
CHCI@VT faculty and students are bolded.
Committee Roles
- Workshops and Tutorials Co-Chair: Chris Brown
- Graduate Consortium Organizer: Chris Brown
- Session Chair: Chris Brown
- Program Committee Members: Chris Brown and Yan Chen
List of Research Papers
- AutoPrint: Judging the Effectiveness of An Automatic Print Statement Debugging Tool
- Catching UX Flaws in Code: Leveraging LLMs to Identify Usability Flaws at the Development Stage
- Designing Conversational AI to Support Think-Aloud Practice in Technical Interview Preparation for CS Students
- Designing Human-AI Collaboration to Support Learning in Counterspeech Writing
- Dynamite: Real-Time Debriefing Slide Authoring through AI-Enhanced Multimodal Interaction
- Programmers Without Borders: Bridging Cultures in Computer Science Study Abroad Program
- Understanding User and Developer Perceptions of Dark Patterns in Online Environments
List of Workshop Contributions
- Do LLM-Generated Resumes Make Me More Qualified? An Observational Study of LLMs For Resume Generation and Matching Tasks
- ParticipantGuide: Promoting Transparency in Human-Centric User Studies
- Understanding User Perceptions of Automated Dark Pattern Detection Online
List of Graduate Consortium Talks
Details of Research Papers
AutoPrint: Judging the Effectiveness of An Automatic Print Statement Debugging Tool
Minhyuk Ko, Omer Ahmed, Yoseph Berhanu Alebachew, Chris Brown
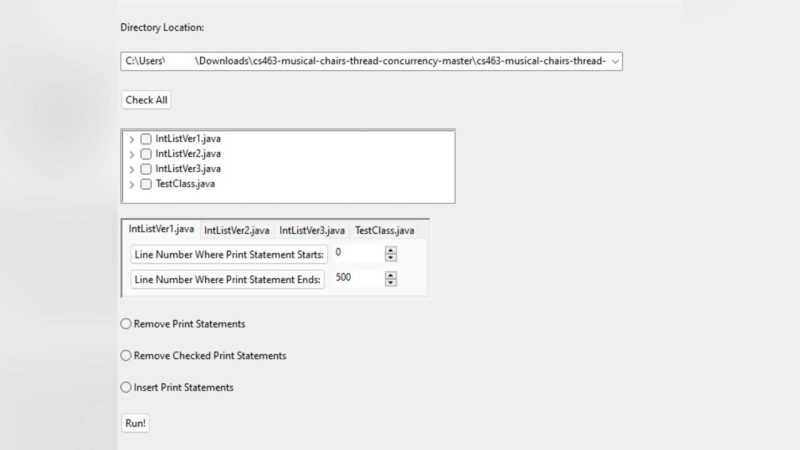
Debugging is one of the most difficult and tedious tasks for software engineers. While various tools and techniques have been introduced to assist debugging, most programmers use print statement debugging to find and fix errors in their code. That is, they manually add code to print values to verify if the code is executing as expected and make sure a certain section of the program is reached. However, this process can be time-consuming and error-prone, especially in large and complex programs. To that end, we introduce AutoPrint, a tool that automatically inserts and removes print statements to streamline print statement debugging in Java code. We conducted a judgment study with 23 participants---students and practitioners---to elicit feedback on AutoPrint and gain insights on its utility in practical debugging tasks. Our results show participants perceive AutoPrint saves debugging time and effort through a faster, simpler, and more usable tool compared to other approaches.
Catching UX Flaws in Code: Leveraging LLMs to Identify Usability Flaws at the Development Stage
Nolan Platt, Ethan Luchs, Sehrish Basir Nizamani
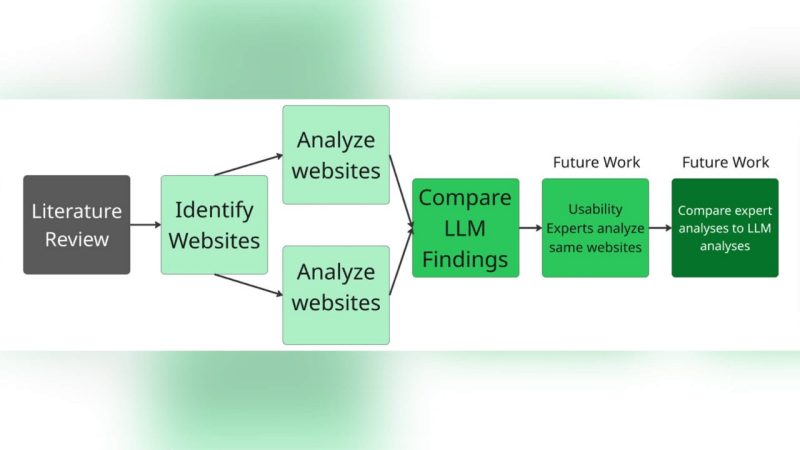
Usability evaluations are essential for ensuring that modern interfaces meet user needs, yet traditional heuristic eval- uations by human experts can be time-consuming and subjective, especially early in development. This paper investigates whether large language models (LLMs) can provide reliable and consistent heuristic assessments at the development stage. By applying Jakob Nielsen’s ten usability heuristics to thirty open-source websites, we generated over 850 heuristic evaluations in three independent evaluations per site using a pipeline of OpenAI’s GPT-4o. For issue detection, the model demonstrated moderate consistency, with an average pairwise Cohen’s Kappa of 0.50 and an exact agreement of 84%. Severity judgments showed more variability: weighted Cohen’s Kappa averaged 0.63, but exact agreement was just 56%, and Krippendorff’s Alpha was near zero. These results suggest that while GPT-4o can produce internally consistent evaluations, especially for identifying the presence of usability issues, its ability to judge severity varies and requires human oversight in practice. Our findings highlight the feasibility and limitations of using LLMs for early-stage, automated usability testing, and offer a foundation for improving consistency in automated User Experience (UX) evaluation. To the best of our knowledge, our work provides one of the first quantitative inter-rater reliability analyses of automated heuristic evaluation and highlights methods for improving model consistency.
Designing Conversational AI to Support Think-Aloud Practice in Technical Interview Preparation for CS Students
Taufiq Daryanto, Sophia Stil, Xiaohan Ding, Daniel Manesh, Sang Won Lee, Tim Lee, Stephanie Lunn, Sarah Rodriguez, Chris Brown, Eugenia Rho
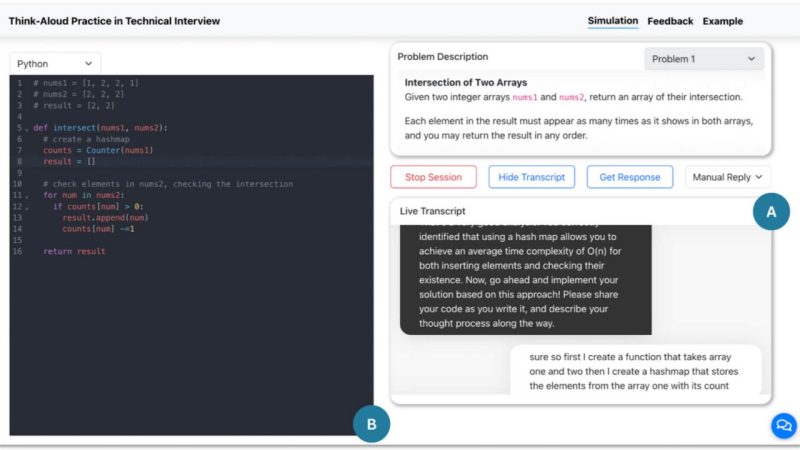
One challenge in technical interviews is the think- aloud process, where candidates verbalize their thought processes while solving coding tasks. Despite its importance, opportunities for structured practice remain limited. Conversational AI offers potential assistance, but limited research explores user perceptions of its role in think-aloud practice. To address this gap, we conducted a study with 17 participants using an LLM-based technical interview practice tool. Participants valued AI’s role in simulation, feedback, and learning from generated examples. Key design recommendations include promoting social presence in conversational AI for technical interview simulation, providing feedback beyond verbal content analysis, and enabling crowdsourced think-aloud examples through human- AI collaboration. Beyond feature design, we examined broader considerations, including intersectional challenges and potential strategies to address them, how AI-driven interview preparation could promote equitable learning in computing careers, and the need to rethink AI’s role in interview practice by suggesting a research direction that integrates human-AI collaboration.
Designing Human-AI Collaboration to Support Learning in Counterspeech Writing
Xiaohan Ding, Kaike Ping, Uma Sushmitha Gunturi, Buse Carik, Lance T Wilhelm, Taufiq Daryanto, Sophia Stil, James Hawdon, Sang Won Lee, Eugenia Rho
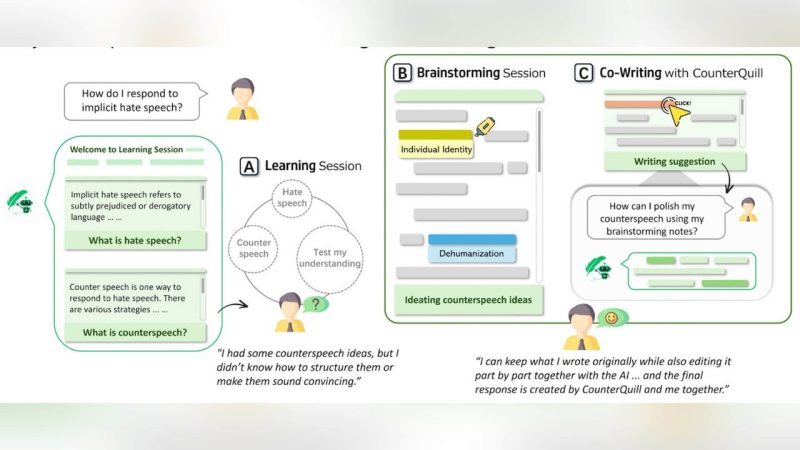
Online hate speech has become increasingly prevalent on social media, causing harm to individuals and society. While automated content moderation has received considerable attention, user-driven counterspeech remains a less explored yet promising approach. However, many people face difficulties in crafting effective responses. We introduce CounterQuill, a human-AI collaborative system that helps everyday users with writing empathetic counterspeech - not by generating automatic replies, but by educating them through reflection and response. CounterQuill follows a three-stage workflow grounded in computational thinking: (1) a learning session to build understanding of hate speech and counterspeech, (2) a brainstorming session to identify harmful patterns and ideate counterspeech ideas, and (3) a co-writing session that helps users refine their counter responses while preserving personal voice. Through a user study (N = 20), we found that CounterQuill helped participants develop the skills to brainstorm and draft counterspeech with confidence and control throughout the process. Our findings highlight how AI systems can scaffold complex communication tasks through structured, human-centered workflows that educate users on how to recognize, reflect on, and respond to online hate speech.
Dynamite: Real-Time Debriefing Slide Authoring through AI-Enhanced Multimodal Interaction
Panayu Keelawat, David Barron, Kaushik Narasimhan, Daniel Manesh, Xiaohang Tang, Xi Chen, Sang Won Lee, Yan Chen
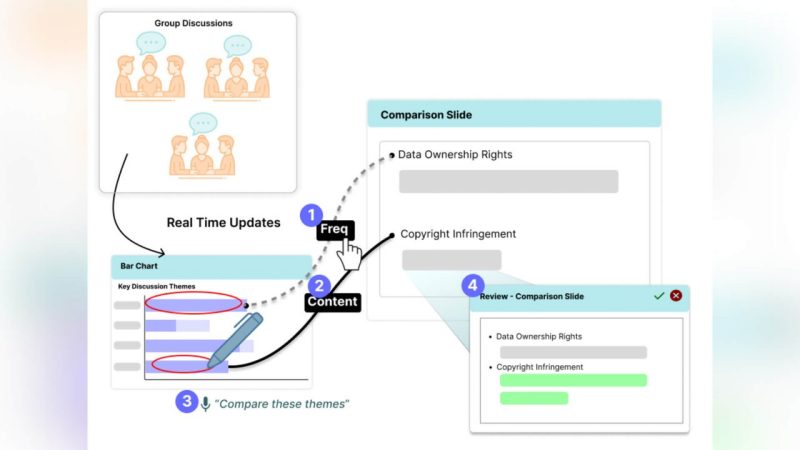
Facilitating class-wide debriefings after small-group discussions is a common strategy in ethics education. Instructor interviews revealed that effective debriefings should highlight frequently discussed themes and surface underrepresented viewpoints, making accurate representations of insight occurrence essential. Yet authoring presentations in real time is cognitively overwhelming due to the volume of data and tight time constraints. We present Dynamite, an AI-assisted system that enables semantic updates to instructor-authored slides during live classroom discussions. These updates are powered by semantic data binding, which links slide content to evolving discussion data, and semantic suggestions, which offer revision options aligned with pedagogical goals. In a within-subject in-lab study with 12 participants, Dynamite outperformed a text-based AI baseline in content accuracy and quality. Participants used voice and sketch input to quickly organize semantic blocks, then applied suggestions to accelerate refinement as data stabilized.
Programmers Without Borders: Bridging Cultures in Computer Science Study Abroad Program
Minhyuk Ko, Mohammed Seyam, Chris Brown

Studying abroad can be a life-changing experience that can help students develop skills, make friends, and gain a global perspective. However, Computer Science (CS) students rarely encounter opportunities to participate in a study abroad program. We interviewed students who participated in our institution's first CS Study Abroad program---focused on software engineering---to understand participants' experiences and how the program impacted the students' personal and computing identities. We found that students faced unique challenges, such as working with teammates who have different cultural backgrounds and programming styles. Through overcoming those challenges, students were able to strengthen their computing identity and gain confidence that they could work in diverse software engineering teams. Based on the lessons that we learned, we provide guidelines to enhance future CS Study Abroad experiences.
Understanding User and Developer Perceptions of Dark Patterns in Online Environments
Huayu Liang, Syeda Afia Hossain, Chris Brown

As dependence on software applications grows, so are the persuasive designs that impact users' experience and decision-making in online user interfaces (UIs). Dark patterns are UI design choices crafted to manipulate or trick users into actions that are not intended. Scholarship on dark patterns is vastly increasing---however, there is limited work on how dark patterns impact users' perceptions and interaction with applications. Furthermore, research has yet to investigate dark patterns from the perspective of software engineers who implement UI designs. We explore users' and developers' perceptions of dark patterns using a mixed-methods approach, surveying each stakeholder group (N_user = 66 and N_developer = 38) and mining GitHub data (N = 2556). Our findings reveal that dark patterns encountered online leave users with limited or no options for avoidance. Developers report that external pressures influence their decisions to implement dark patterns, and most recognize their adverse effects on trust and user experiences (UX), often reflecting negative sentiments in software projects. Our findings shed light on mitigating deceptive designs in online interfaces that are increasingly essential in people's daily lives. Study artifacts—including surveys, GitHub data, and data collection scripts—are available online.
Details of Workshop Contributions
Do LLM-Generated Resumes Make Me More Qualified? An Observational Study of LLMs For Resume Generation and Matching Tasks
Swanand Vaishampayan, Chris Brown

Large Language Models (LLMs) are gaining traction in various hiring-related tasks for both candidates and employers. For instance, employers are increasingly using LLMs to rate applicants based on the match between their resume content and job description requirements. Meanwhile, candidates use LLMs to write cover letters and tailor resume content. However, research shows LLMs can impart biases against minorities, such as generating lower rankings for disabled candidates or “resume whitening” to minimize diversity aspects of candidates’ identities in hiring contexts. Thus, we conducted an observational study to investigate how widely used LLMs – GPT-4, Gemini and Claude – perform in supporting resume tasks for employers and candidates. Using a real-world dataset of job descriptions and resumes from disabled (n = 209) and non-disabled (n = 209) candidates, we examine the capabilities of these models across resume rating and resume generation tasks in a zero-shot setting. Our main findings show moderate alignment across models for resume matching and no significant differences in ratings between disabled and non-disabled candidates. However, we did observe increased ratings for LLM-generated resumes for GPT-4 and Claude. We discuss the implications for both candidates and employers based on our findings, aiming to promote non-biased and equitable AI-based hiring processes and motivate human-AI collaboration in the design of future hiring systems.
ParticipantGuide: Promoting Transparency in Human-Centric User Studies
Minhyuk Ko, Shawal Khalid, Chris Brown

Human subjects research is fundamental to advancing human-computer interaction (HCI), as it helps researchers understand user behaviors, needs, and experiences to enhance the design of software products. However, conducting such human-centric studies is often hindered by challenges in participant recruitment, including inefficiencies in finding eligible participants and administrative burdens. Participants are hindered from joining research studies due to logistical, eligibility, communication, or personal barriers that make participation impractical, inaccessible, or unappealing. These barriers not only slow down research progress, but also limit the diversity and representativeness of study participants. To address these issues, we propose ParticipantGuide—a structured label-based approach to enhance participant recruitment through providing key and interpretable information to potential participants. We discuss existing work, present a preliminary design, and provide implications for future research.
Understanding User Perceptions of Automated Dark Pattern Detection Online
Ryan Wood, Chris Brown
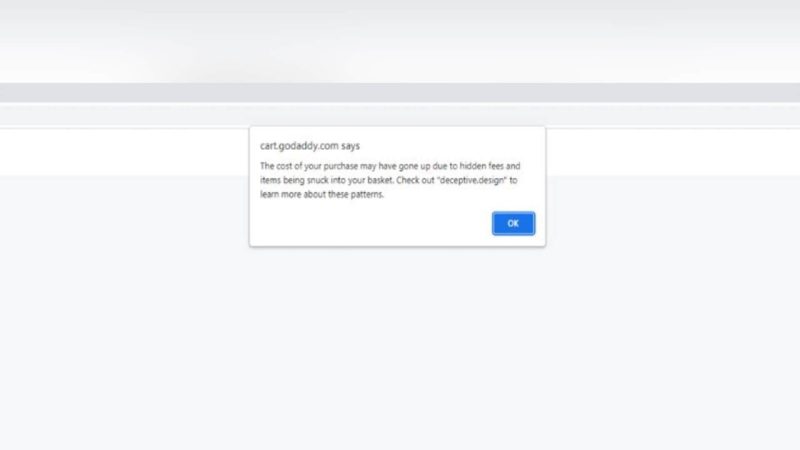
Dark patterns are software designs intended to manipulate and mislead users of digital applications. These patterns range from making it harder to end a subscription service, adding additional charges to a purchase, or having the user give out data or personal information. Prior work explores perceptions of dark patterns, yet there is limited research exploring the effects of tooling to detect dark patterns on users. In this study, we introduced Dark Pattern Detector, a Google Chrome extension that would help users detect and understand dark patterns online. We conducted a technology probe study where participants (n = 40) were tasked with installing the extension and completing a series of tasks on different websites based on real-world Internet browsing. We leveraged mixed-methods surveys to collect feedback on dark pattern detection tools in practice. We found the majority of participants gave positive feedback, claiming they found the extension useful, interesting, and a good idea. Many participants also gave useful feedback about what changes or additions they would like to see in future systems. With our results, we provide implications to help users better understand dark patterns and motivate future tools for enhancing dark pattern detection in online environments.
Details of Graduate Consortium Talks
AI-Guided Exploration of Large-Scale Codebases
Yoseph Berhanu Alebachew
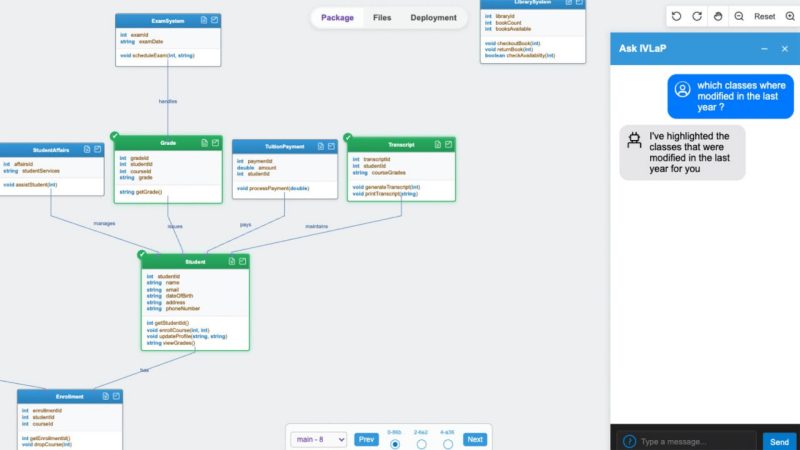
Understanding large-scale, complex software systems is a major challenge for developers, who spend a significant portion of their time on program comprehension. Traditional tools such as static visualizations and reverse engineering techniques provide structural insights but often lack interactivity, adaptability, and integration with contextual information. Recent advancements in large language models (LLMs) offer new opportunities to enhance code exploration workflows, yet their lack of grounding and integration with structured views limits their effectiveness. In this graduate consortium presentation, we introduce a hybrid approach that integrates deterministic reverse engineering with LLM-guided, intent-aware visual exploration. The proposed system combines UML-based visualization, dynamic user interfaces, historical context, and collaborative features into an adaptive tool for code comprehension. By interpreting user queries and interaction patterns, the LLM helps developers navigate and understand complex codebases more effectively. A prototype implementation demonstrates the feasibility of this approach. Future work includes empirical evaluation, scaling to polyglot systems, and exploring GUI-driven LLM interaction models. This research lays the groundwork for intelligent, interactive environments that align with developer cognition and collaborative workflows.
Related Content
-
General Item




