

CHCI Participation in HFES ‘23
November 8, 2023

Multiple CHCI faculty and student members (in bold below) all from the Department of Industrial and Systems Engineering, presented research papers and posters at the 67th International Annual Meeting of the Human Factors and Ergonomics Society held during October 23 - 27, 2023 in Washington D.C. The HFES Student Chapter at Virginia Tech got the Silver Level Award from the Human Factors and Ergonomics Society. The paper by Manhua Wang, Ravi Parikh, and Myounghoon Jeon titled ‘Using Multilevel Hidden Markov Models to Understand Driver Hazard Avoidance during the Takeover Process in Conditionally Automated Vehicles’ received the Alphonse Chapanis Best Student Paper Award!

Papers
Cognitive Workload of Novice Forklift Truck Drivers in VR-based Training
Authors: Saman Jamshid Nezhad Zahabi, Md Shafiqul Islam, Sunwook Kim, Nathan Lau, Maury Nussbaum, Sol Lim
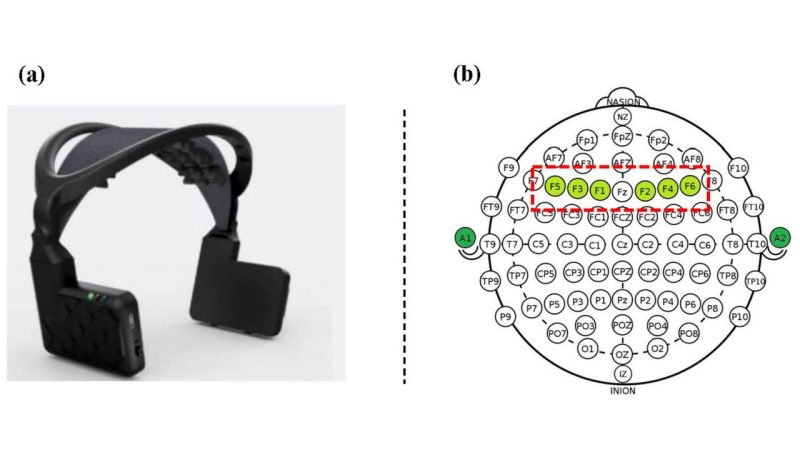
There is increasing use of Virtual Reality (VR) to train forklift truck operators but a lack of sufficient understanding of how cognitive workload changes with respect to different task demands in VR-based training. In this study, 19 novice participants completed three forklift driving lessons with varying difficulty levels (low, medium, and high) using a VR simulator. To examine the effect of repeated training on cognitive workload, two sessions were repeated by participants using the same procedures. Cognitive workload was assessed with objective (electroencephalogram [EEG] activity) and subjective (NASA-TLX) measurements. EEG theta power and NASA-TLX (mental workload) scores were significantly higher for high than low difficulty levels. However, both EEG and NASA-TLX responses were reduced with repeated training in the second session. These findings highlight the effectiveness of EEG in continuous monitoring of workload variation caused by task difficulty and implementing training programs to moderate cognitive workload for forklift operators.
Forklift Driving Performance of Novices with Repeated VR-based Training
Authors: Md Shafiqul Islam, Saman Jamshid Nezhad Zahabi, Sunwook Kim, Nathan Lau, Maury Nussbaum, Sol Lim
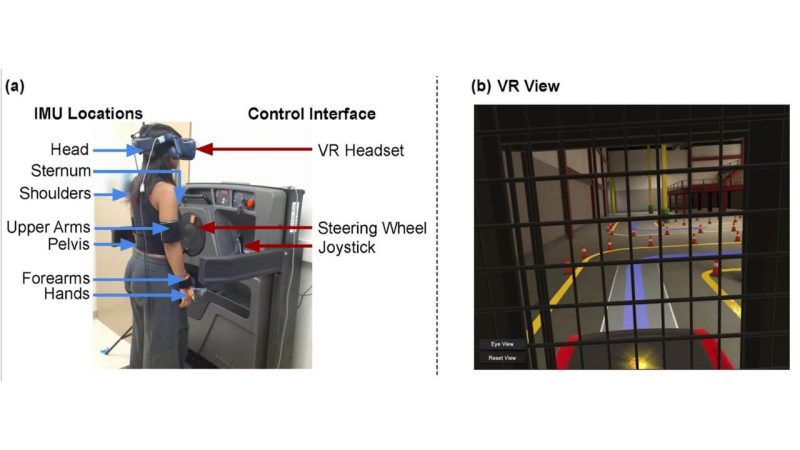
Virtual reality (VR) has emerged as a promising tool for training novice forklift drivers, but temporal patterns of such improvements are largely unknown. We trained 19 novice participants using an order-picker VR simulator on a selected driving lesson. In two sessions, participant driving performance was assessed using task completion time and kinematics of the head, shoulder, and lumbar spine via inertial measurement units (IMUs). Completion time and head flexion/movement decreased significantly (up to 22.4% and 31.5%, respectively). The observed changes in head motion (flexion/extension) indicate an initial adjustment period to prepare a mental model of the driving task and the control panel, which was also adapted over repeated trials. One implication of our results is that reduced head flexion/extension could be used as an indication of a novice driver’s improved skill during the early stages of training, in terms of familiarizing themselves with vehicle control and the vehicle control panel.
Comparing Armband EMG-based Lifting Load Classification Algorithms using Various Lifting Trials
Authors: Sakshi Pranay Taori, Sol Lim
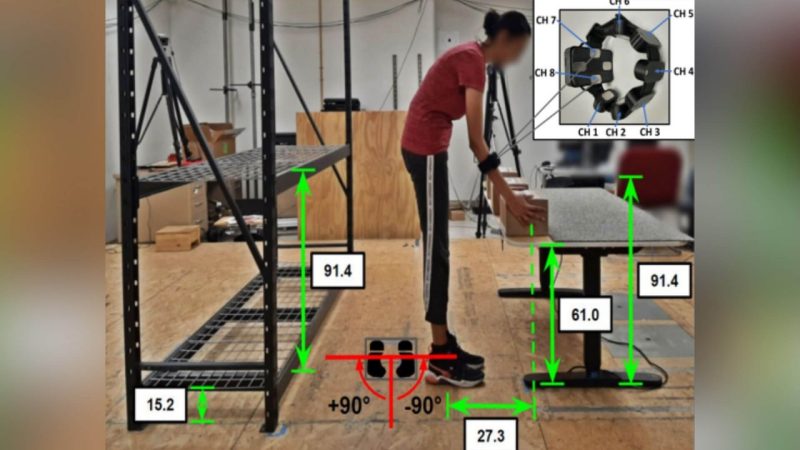
The objective of this study was to evaluate the performance of machine learning (ML) algorithms developed using surface electromyography (EMG) armband sensor data in predicting hand-load levels (5 lb and 15 lb) from diverse lifting trials. Twelve healthy participants (six male and six female) performed repetitive lifting with three different lifting conditions, i.e., symmetric (S), asymmetric (A), and free-dynamic (F) lifts. ML models were developed with four lifting datasets (S, A, S+A, and F) and were cross-validated using F as the test dataset. Mean classification accuracy was significantly lower in models developed with the S dataset (78.8%) compared to A (83.2%) and F (83.4%). Findings indicate that the ML model developed with controlled symmetric lifts was less accurate in predicting the load of more dynamic, unconstrained lifts, which is common in real-world settings.
Enhancing Art Gallery Visitors' Experiences through Audio Augmented Reality Technology
Authors: Abhraneil Dam, Yeaji Lee, Arsh Siddiqui, Wallace Santos Lages, Myounghoon Jeon

Audio Augmented Reality (AAR) applications are gaining traction, especially for entertainment purposes. To that extent, the current study explored its use and effectiveness in enhancing art gallery visitors’ experiences. Four paintings were selected and sonified using the Jython algorithm to produce computer generated music (Basic AAR); the audio was then further enhanced with traditional music by a musician (Enhanced AAR). Twenty-six participants experienced each painting in Basic, Enhanced, and No AAR condition. Results show that AAR cues had a significant effect on participants’ subjective feedback towards the paintings. Sentiment Analysis shows that participants mentioned significantly more positive words from Enhanced AAR than the others. Enhanced AAR also made participants express a sense of immersion, whereas Basic AAR made them concentrate more on forlorn aspects of the paintings. Findings from this study suggest ways to improve and customize AAR cues for different painting styles, and indicate the need for multi-modal augmentations.
Using Multilevel Hidden Markov Models to Understand Driver Hazard Avoidance during the Takeover Process in Conditionally Automated Vehicles
Authors: Manhua Wang, Ravi Parikh, Myounghoon Jeon
[Received Alphonse Chapanis Best Student Paper Award]
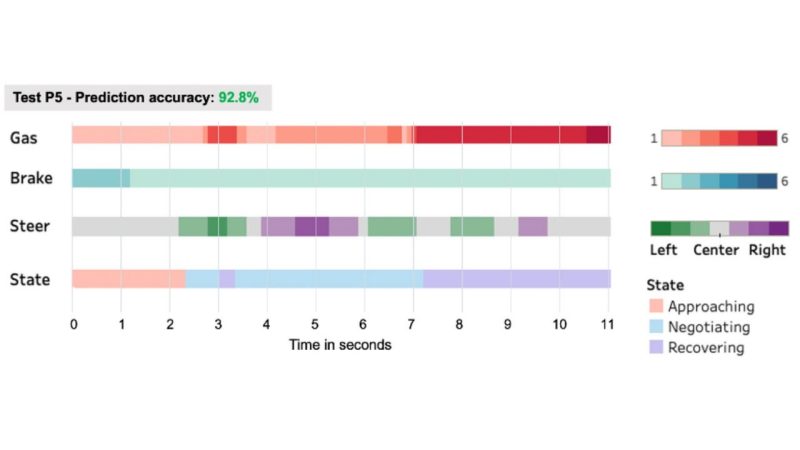
Ensuring a safe transition between the automation system and human operators is critical in conditionally automated vehicles. During the automation-to-human transition process, hazard avoidance plays an important role after human drivers regain the vehicle control. This study applies the multilevel Hidden Markov Model to understand the hazard avoidance processes in response to static road hazards as continuous processes. The three-state model—Approaching, Negotiating, and Recovering—had the best model fitness, compared to the four-state and five-state models. The trained model reaches an average of 66% accuracy rate on predicting hazard avoidance states on the testing data. The prediction performance reveals the possibility to use the hazard avoidance pattern to recognize driving behaviors. We further propose several improvements at the end to generalize our models into other scenarios, including the potential to model hazard avoidance as a basic driving skill across different levels of automation conditions.
Assessing Laparoscopic Surgical Skills of Trainees with Scene Independent and Dependent Eye Gaze Metrics
Authors: Shiyu Deng, Jinwoo Oh, Tianzi Wang, Sarah Parker, Nathan Lau

Eye tracking metrics have been used to objectively evaluate proficiency levels in psychomotor tasks, including aviation, driving, sports, and surgery. Despite extensive research devoted to developing and utilizing eye metrics, the literature does not contain any explicit comparison between scene independent and dependent eye metrics for understanding skill acquisition or characterizing expertise. This study collected eye tracking data from medical students practicing the peg transfer task and computed both scene independent and dependent eye metrics to indicate proficiency. K-means clustering analysis on the eye metrics yielded three clusters corresponding to three proficiency levels which showed significantly different trial completion time. The box plots of the eye-gaze metrics illustrated different patterns of scene independent and dependent eye metrics with respect to proficiency levels, highlighting the need for further examination of these metrics for more accurate and useful applications.
Facial Expressions Increase Emotion Recognition Clarity and Improve Warmth and Attractiveness on a Humanoid Robot without Adding the Uncanny Valley
Authors: Jiayuan Dong, Alex Santiago-Anaya, Myounghoon Jeon

With the rising impact of social robots, research on understanding user perceptions and preferences of these robots gains further importance, especially for emotional expressions. However, research on facial expressions and their effects on human-robot interaction has had mixed results. To unpack this issue further, we investigated users’ emotion recognition accuracy and perceptions when interacting with a social robot that displayed emotional facial expressions or not in a storytelling setting. In our experiment, twenty-eight participants received verbal feedback either with or without facial expressions from the robot. Participants showed a significant recognition accuracy effect for emotions and significantly higher clarity for disgust, happiness, and surprise in the facial expression condition than in the no facial expression condition. In addition, participants rated Milo with facial expressions significantly higher than Milo without facial expressions in warmth and attractiveness. No significant differences were found among the rating scores of naturalness. The results from the present study indicated the importance of facial expressions when considering design choices in social robots.
Posters
Feeling Your Way with Navibar: A Navigation System using Vibrotactile Feedback for Personal Mobility Vehicle Users
Authors: Mungyeong Choe, Ajit Gopal, Abdulmajid Badahdah, Esha Mahendran, Darrian Burnett, Myounghoon Jeon
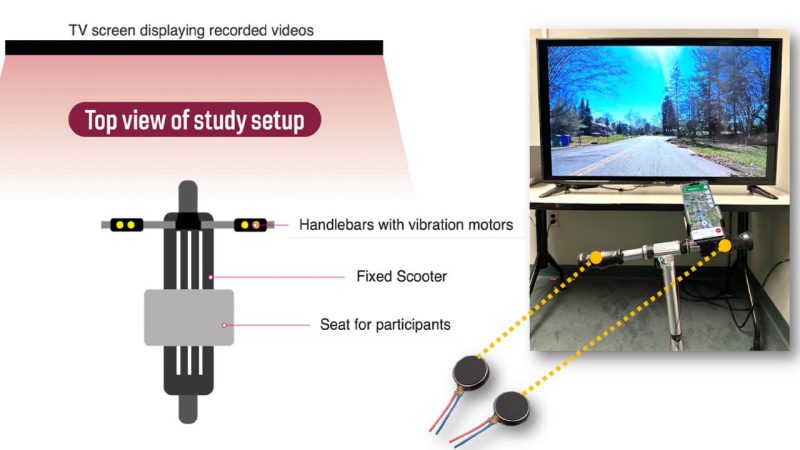
Navigating routes using navigation systems while using Personal Mobility Vehicles (PMVs) like bikes or scooters can lead to visual distraction in outdoor environments, creating possibilities for an accident. This article proposes a new navigation system called NaVibar for PMVs that uses vibrotactile feedback on the handlebar to enhance route information delivery and reduce visual distraction. The study aims to answer four research questions about visual distraction, route recognition, mental workload, and usability. The results of the study showed that vibrotactile feedback can be an effective and useful addition to the PMVs navigation system, reducing visual distraction, and enhancing the user experience. Also, vibrotactile feedback did not affect the participants' route recognition, but it positively affected the participants’ lower workload levels. Therefore, our study demonstrates that the addition of vibrotactile feedback could enhance the usability and safety of PMV navigation systems.
The Influence of Olfactory and Visual Stimuli on Students’ Performance and Mood in Virtual Reality Environment
Authors: Hayoun Moon, Mohamad Sadra Rajabi, Shokoufeh Bozorgmehrian, Mohammadreza Freidouny, Ankit Sangwan, Myounghoon Jeon

Exposure to sensory stimuli such as aromatherapy and immersion in Virtual Reality (VR) has shown impacts on task performance and emotional state. In this study, we examined the effects of stimuli types (olfactory, visual, and both) and themes (forest and café) in a VR environment to improve students’ performance and mood. While both the stimuli type and theme had no influence on the performance of the Stroop Test, providing olfactory with visual stimuli did increase the level of awakeness compared to providing visuals only or olfactory only. The choice of theme was an important factor in affecting mood; presenting the forest theme made participants feel better, more awake, and calmer compared to presenting the café theme. No interaction effect of stimuli and the theme was observed in any of the studied measurements. More complex tasks should be further tested to see whether the aforementioned stimuli can have effects on students’ performance.
See You on the Other Side: A Crosswalk Navigation System with Multimodal Alert System for Distracted and Visually Impaired Crosswalk Users
Authors: Alec Werner, Md Shafiqul Islam, Anvitha Nachiappan, Tanishq Bafna, Maryam Movassagh, Myounghoon Jeon
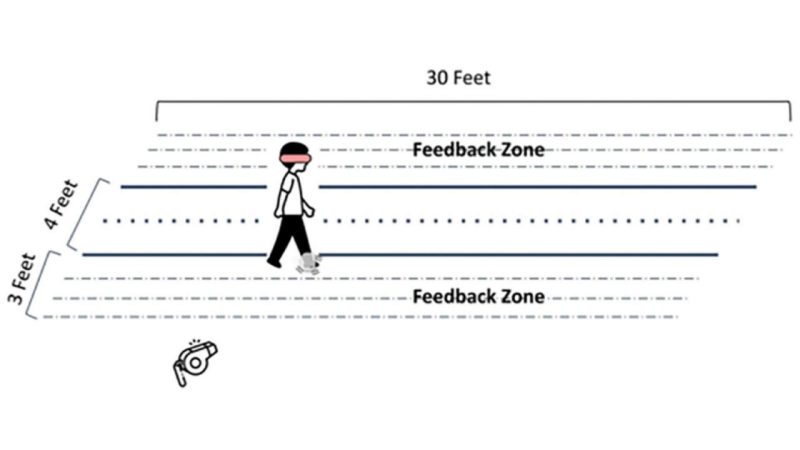
Distracted and visually impaired crosswalk users are at increased injury and death risk. A system that redirects the attention of distracted crosswalk users and helps both distracted and visually-impaired crosswalk users safely navigate crosswalks could mitigate that risk. We tested the effectiveness of four feedback systems on crosswalk navigation: no feedback (baseline), auditory (whistle), vibrotactile, and multimodal (auditory and vibrotactile). Twelve participants were recruited and blindfolded to cross an in-lab mock crosswalk. Analysis showed that multimodal auditory and vibrotactile feedback significantly increased the success rate of navigating through a crosswalk compared to the baseline. Among the participants, 83.3% (10 participants) preferred vibrotactile feedback, and 75% (9 participants) found vibrotactile feedback to be most intuitive. These findings can inform the development of infrastructure-embedded alert systems that promote the safety of distracted crosswalk users.
In addition to all the authors listed above, ISE students Mahdis Tajdari and Junghoon Chung also attended the event.